protobuf中的数据编解码解析
2014-07-16
Demo
我们使用Message的以下两个函数来了解数据的序列化和反序列化:
bool Message::SerializeToOstream(ostream* output) const;
bool Message::ParseFromIstream(istream* input);
SerializeToOstream
//message.cc
bool Message::SerializeToOstream(ostream* output) const {
{
io::OstreamOutputStream zero_copy_output(output);
if (!SerializeToZeroCopyStream(&zero_copy_output)) return false;
}
return output->good();
}
//message_lite.cc
bool MessageLite::SerializeToZeroCopyStream(io::ZeroCopyOutputStream* output) const {
io::CodedOutputStream encoder(output);
return SerializeToCodedStream(&encoder);
}
bool MessageLite::SerializeToCodedStream(io::CodedOutputStream* output) const {
GOOGLE_DCHECK(IsInitialized()) << InitializationErrorMessage("serialize", *this);
return SerializePartialToCodedStream(output);
}
bool MessageLite::SerializePartialToCodedStream( io::CodedOutputStream* output) const {
const int size = ByteSize(); // Force size to be cached. 首先获得这个消息的size
uint8* buffer = output->GetDirectBufferForNBytesAndAdvance(size); //拿到Buffer
if (buffer != NULL) {
uint8* end = SerializeWithCachedSizesToArray(buffer);
if (end - buffer != size) {
ByteSizeConsistencyError(size, ByteSize(), end - buffer);
}
return true;
} else { // buffer size 不够
int original_byte_count = output->ByteCount();
SerializeWithCachedSizes(output);
if (output->HadError()) {
return false;
}
int final_byte_count = output->ByteCount();
if (final_byte_count - original_byte_count != size) {
ByteSizeConsistencyError(size, ByteSize(),
final_byte_count - original_byte_count);
}
return true;
}
}
SerializeWithCachedSizesToArray(char *)// 这个方法更快,不需要每次边界检查
SerializeWithCachedSizes(CodedOutputStream)
uint8* MessageLite::SerializeWithCachedSizesToArray(uint8* target) const {
// We only optimize this when using optimize_for = SPEED. In other cases
// we just use the CodedOutputStream path.
int size = GetCachedSize();
io::ArrayOutputStream out(target, size);
io::CodedOutputStream coded_out(&out);
SerializeWithCachedSizes(&coded_out);
GOOGLE_CHECK(!coded_out.HadError());
return target + size;
}
回到message.h
//message.h
void Message::SerializeWithCachedSizes(io::CodedOutputStream* output) const {
WireFormat::SerializeWithCachedSizes(*this, GetCachedSize(), output);
}
int Message::ByteSize() const {
int size = WireFormat::ByteSize(*this);
SetCachedSize(size);
return size;
}
void Message::SetCachedSize(int size) const {
GOOGLE_LOG(FATAL) << "Message class \"" << GetDescriptor()->full_name()
<< "\" implements neither SetCachedSize() nor ByteSize(). "
"Must implement one or the other.";
}
GetCachedSize()的定义没有看到
主要序列化方法为:WireFormat::SerializeWithCachedSizes()
// Serialize a message in protocol buffer wire format.
//
// Any embedded messages within the message must have their correct sizes
// cached. However, the top-level message need not; its size is passed as
// a parameter to this procedure.
//
// These return false iff the underlying stream returns a write error.
static void SerializeWithCachedSizes(
const Message& message,
int size, io::CodedOutputStream* output);
wire_format.cc中:
void WireFormat::SerializeWithCachedSizes(
const Message& message,
int size, io::CodedOutputStream* output) {
const Descriptor* descriptor = message.GetDescriptor();
const Reflection* message_reflection = message.GetReflection();
int expected_endpoint = output->ByteCount() + size; //应该出现的终点
vector<const FieldDescriptor*> fields;
//ListFields方法只有field被set的时候才会有
message_reflection->ListFields(message, &fields);
for (int i = 0; i < fields.size(); i++) {
SerializeFieldWithCachedSizes(fields[i], message, output);//序列化每个字段
}
if (descriptor->options().message_set_wire_format()) {
SerializeUnknownMessageSetItems(
message_reflection->GetUnknownFields(message), output);
} else {
SerializeUnknownFields(
message_reflection->GetUnknownFields(message), output);//序列化UnknownFields
}
GOOGLE_CHECK_EQ(output->ByteCount(), expected_endpoint)
<< ": Protocol message serialized to a size different from what was "
"originally expected. Perhaps it was modified by another thread "
"during serialization?";
}
先看WireFormat::SerializeFieldWithCachedSizes(FieldDescriptor,Message,CodedOutputStream*):
void WireFormat::SerializeFieldWithCachedSizes(
const FieldDescriptor* field,
const Message& message,
io::CodedOutputStream* output) {
const Reflection* message_reflection = message.GetReflection();
if (field->is_extension() &&
field->containing_type()->options().message_set_wire_format() &&
field->cpp_type() == FieldDescriptor::CPPTYPE_MESSAGE &&
!field->is_repeated()) {
SerializeMessageSetItemWithCachedSizes(field, message, output);
return;
} // 兼容WireFormat的,不用管
int count = 0;
if (field->is_repeated()) {
count = message_reflection->FieldSize(message, field);
} else if (message_reflection->HasField(message, field)) {
count = 1;
}
const bool is_packed = field->options().packed();
if (is_packed && count > 0) {
//写一个( (number << 3) | WIRETYPE_LENGTH_DELIMITED)
WireFormatLite::WriteTag(field->number(),
WireFormatLite::WIRETYPE_LENGTH_DELIMITED, output);
//得到Filed的size
const int data_size = FieldDataOnlyByteSize(field, message);
//写一个varint 32
output->WriteVarint32(data_size);
}
//由下面的代码可以看出,repeated的packed属性,仅仅对于 primitive和enum有用,对于string,message这种不能自解释的类型,即使加了packed,后面还是要写tag的。packed的作用就是如果是int repeated,那么这个列表整体共享一个tag。
for (int j = 0; j < count; j++) {
switch (field->type()) {
//对于每种primitive类型,调用对应的Write函数来写
#define HANDLE_PRIMITIVE_TYPE(TYPE, CPPTYPE, TYPE_METHOD, CPPTYPE_METHOD) \
case FieldDescriptor::TYPE_##TYPE: { \
const CPPTYPE value = field->is_repeated() ? \
message_reflection->GetRepeated##CPPTYPE_METHOD( \
message, field, j) : \
message_reflection->Get##CPPTYPE_METHOD( \
message, field); \
if (is_packed) { \
WireFormatLite::Write##TYPE_METHOD##NoTag(value, output); \
} else { \
WireFormatLite::Write##TYPE_METHOD(field->number(), value, output); \
} \
break; \
}
HANDLE_PRIMITIVE_TYPE( INT32, int32, Int32, Int32)
HANDLE_PRIMITIVE_TYPE( INT64, int64, Int64, Int64)
HANDLE_PRIMITIVE_TYPE(SINT32, int32, SInt32, Int32)
HANDLE_PRIMITIVE_TYPE(SINT64, int64, SInt64, Int64)
HANDLE_PRIMITIVE_TYPE(UINT32, uint32, UInt32, UInt32)
HANDLE_PRIMITIVE_TYPE(UINT64, uint64, UInt64, UInt64)
HANDLE_PRIMITIVE_TYPE( FIXED32, uint32, Fixed32, UInt32)
HANDLE_PRIMITIVE_TYPE( FIXED64, uint64, Fixed64, UInt64)
HANDLE_PRIMITIVE_TYPE(SFIXED32, int32, SFixed32, Int32)
HANDLE_PRIMITIVE_TYPE(SFIXED64, int64, SFixed64, Int64)
HANDLE_PRIMITIVE_TYPE(FLOAT , float , Float , Float )
HANDLE_PRIMITIVE_TYPE(DOUBLE, double, Double, Double)
HANDLE_PRIMITIVE_TYPE(BOOL, bool, Bool, Bool)
#undef HANDLE_PRIMITIVE_TYPE
#define HANDLE_TYPE(TYPE, TYPE_METHOD, CPPTYPE_METHOD) \
case FieldDescriptor::TYPE_##TYPE: \
WireFormatLite::Write##TYPE_METHOD( \
field->number(), \
field->is_repeated() ? \
message_reflection->GetRepeated##CPPTYPE_METHOD( \
message, field, j) : \
message_reflection->Get##CPPTYPE_METHOD(message, field), \
output); \
break;
HANDLE_TYPE(GROUP , Group , Message)
HANDLE_TYPE(MESSAGE, Message, Message)
#undef HANDLE_TYPE
case FieldDescriptor::TYPE_ENUM: {
const EnumValueDescriptor* value = field->is_repeated() ?
message_reflection->GetRepeatedEnum(message, field, j) :
message_reflection->GetEnum(message, field);
if (is_packed) {
WireFormatLite::WriteEnumNoTag(value->number(), output);
} else {
WireFormatLite::WriteEnum(field->number(), value->number(), output);
}
break;
}
// Handle strings separately so that we can get string references
// instead of copying.
case FieldDescriptor::TYPE_STRING: {
string scratch;
const string& value = field->is_repeated() ?
message_reflection->GetRepeatedStringReference(
message, field, j, &scratch) :
message_reflection->GetStringReference(message, field, &scratch);
VerifyUTF8String(value.data(), value.length(), SERIALIZE);
WireFormatLite::WriteString(field->number(), value, output);
break;
}
case FieldDescriptor::TYPE_BYTES: {
string scratch;
const string& value = field->is_repeated() ?
message_reflection->GetRepeatedStringReference(
message, field, j, &scratch) :
message_reflection->GetStringReference(message, field, &scratch);
WireFormatLite::WriteBytes(field->number(), value, output);
break;
}
}
}
}
再看看WireFormat::SerializeUnknownFields(UnknownFieldSet, CodeOutputStream*)
void WireFormat::SerializeUnknownFields(const UnknownFieldSet& unknown_fields,
io::CodedOutputStream* output) {
for (int i = 0; i < unknown_fields.field_count(); i++) {
const UnknownField& field = unknown_fields.field(i);
switch (field.type()) {
case UnknownField::TYPE_VARINT:
output->WriteVarint32(WireFormatLite::MakeTag(field.number(),
WireFormatLite::WIRETYPE_VARINT));
output->WriteVarint64(field.varint());
break;
case UnknownField::TYPE_FIXED32:
output->WriteVarint32(WireFormatLite::MakeTag(field.number(),
WireFormatLite::WIRETYPE_FIXED32));
output->WriteLittleEndian32(field.fixed32());
break;
case UnknownField::TYPE_FIXED64:
output->WriteVarint32(WireFormatLite::MakeTag(field.number(),
WireFormatLite::WIRETYPE_FIXED64));
output->WriteLittleEndian64(field.fixed64());
break;
case UnknownField::TYPE_LENGTH_DELIMITED:
output->WriteVarint32(WireFormatLite::MakeTag(field.number(),
WireFormatLite::WIRETYPE_LENGTH_DELIMITED));
output->WriteVarint32(field.length_delimited().size());
output->WriteString(field.length_delimited());
break;
case UnknownField::TYPE_GROUP:
output->WriteVarint32(WireFormatLite::MakeTag(field.number(),
WireFormatLite::WIRETYPE_START_GROUP));
SerializeUnknownFields(field.group(), output);
output->WriteVarint32(WireFormatLite::MakeTag(field.number(),
WireFormatLite::WIRETYPE_END_GROUP));
break;
}
}
}
google/protobuf/wire_format_lite_inl.h中:
inline void WireFormatLite::WriteTag(int field_number, WireType type,
io::CodedOutputStream* output) {
output->WriteTag(MakeTag(field_number, type));
}
/wire_format.lite.h中
inline uint32 WireFormatLite::MakeTag(int field_number, WireType type) {
return GOOGLE_PROTOBUF_WIRE_FORMAT_MAKE_TAG(field_number, type);
}
// This macro does the same thing as WireFormatLite::MakeTag(), but the
// result is usable as a compile-time constant, which makes it usable
// as a switch case or a template input. WireFormatLite::MakeTag() is more
// type-safe, though, so prefer it if possible.
#define GOOGLE_PROTOBUF_WIRE_FORMAT_MAKE_TAG(FIELD_NUMBER, TYPE) \
static_cast<uint32>( \
((FIELD_NUMBER) << ::google::protobuf::internal::WireFormatLite::kTagTypeBits) \
| (TYPE))
// Number of bits in a tag which identify the wire type.使用3个bit来指定wire type
static const int kTagTypeBits = 3;
// WireType的几个类型
enum WireType {
WIRETYPE_VARINT = 0,
WIRETYPE_FIXED64 = 1,
WIRETYPE_LENGTH_DELIMITED = 2,
WIRETYPE_START_GROUP = 3,
WIRETYPE_END_GROUP = 4,
WIRETYPE_FIXED32 = 5,
};
WireFormat::FieldDataOnlyByteSize
CodedOutputStream::WriteVarint64
如果是packed,WireFormatLite::WriteUInt32NoTag(value,output)
wireFormatLite::WriteUInt32(field->number(),value,output)
void WireFormatLite::WriteInt32(int field_number, int32 value,
io::CodedOutputStream* output) {
WriteTag(field_number, WIRETYPE_VARINT, output);
WriteInt32NoTag(value, output);
}
inline void WireFormatLite::WriteUInt32NoTag(uint32 value,
io::CodedOutputStream* output) {
output->WriteVarint32(value);
}
void WireFormatLite::WriteString(int field_number, const string& value,
io::CodedOutputStream* output) {
// String is for UTF-8 text only
WriteTag(field_number, WIRETYPE_LENGTH_DELIMITED, output);
GOOGLE_CHECK(value.size() <= kint32max);
output->WriteVarint32(value.size());
output->WriteString(value);
}
void WireFormatLite::WriteGroup(int field_number,
const MessageLite& value,
io::CodedOutputStream* output) {
WriteTag(field_number, WIRETYPE_START_GROUP, output);
value.SerializeWithCachedSizes(output);
WriteTag(field_number, WIRETYPE_END_GROUP, output);
}
void WireFormatLite::WriteMessage(int field_number,
const MessageLite& value,
io::CodedOutputStream* output) {
WriteTag(field_number, WIRETYPE_LENGTH_DELIMITED, output);
const int size = value.GetCachedSize();
output->WriteVarint32(size);
value.SerializeWithCachedSizes(output);
}
到此,一个Message的序列化就已经分析完了。有空可以写一下每中类型都是采用何种序列化方法序列化的。(TODO)
enum WireType {
WIRETYPE_VARINT = 0,
WIRETYPE_FIXED64 = 1,
WIRETYPE_LENGTH_DELIMITED = 2,
WIRETYPE_START_GROUP = 3,
WIRETYPE_END_GROUP = 4,
WIRETYPE_FIXED32 = 5,
};
// Lite alternative to FieldDescriptor::Type. Must be kept in sync.
enum FieldType {
TYPE_DOUBLE = 1,
TYPE_FLOAT = 2,
TYPE_INT64 = 3,
TYPE_UINT64 = 4,
TYPE_INT32 = 5,
TYPE_FIXED64 = 6,
TYPE_FIXED32 = 7,
TYPE_BOOL = 8,
TYPE_STRING = 9,
TYPE_GROUP = 10,
TYPE_MESSAGE = 11,
TYPE_BYTES = 12,
TYPE_UINT32 = 13,
TYPE_ENUM = 14,
TYPE_SFIXED32 = 15,
TYPE_SFIXED64 = 16,
TYPE_SINT32 = 17,
TYPE_SINT64 = 18,
MAX_FIELD_TYPE = 18,
};
// Lite alternative to FieldDescriptor::CppType. Must be kept in sync.
enum CppType {
CPPTYPE_INT32 = 1,
CPPTYPE_INT64 = 2,
CPPTYPE_UINT32 = 3,
CPPTYPE_UINT64 = 4,
CPPTYPE_DOUBLE = 5,
CPPTYPE_FLOAT = 6,
CPPTYPE_BOOL = 7,
CPPTYPE_ENUM = 8,
CPPTYPE_STRING = 9,
CPPTYPE_MESSAGE = 10,
MAX_CPPTYPE = 10,
};
ParseFromIstream
//messge.cc line 130
bool Message::ParseFromIstream(istream* input) {
io::IstreamInputStream zero_copy_input(input);
return ParseFromZeroCopyStream(&zero_copy_input) && input->eof();
}
//message_lite.cc line 168
bool MessageLite::ParseFromZeroCopyStream(io::ZeroCopyInputStream* input) {
io::CodedInputStream decoder(input);
return ParseFromCodedStream(&decoder) && decoder.ConsumedEntireMessage();
}
//message_lite.h
bool MessageLite::ParseFromCodedStream(io::CodedInputStream* input) {
return InlineParseFromCodedStream(input, this);
}
bool InlineMergeFromCodedStream(io::CodedInputStream* input,
MessageLite* message) {
if (!message->MergePartialFromCodedStream(input)) return false;
if (!message->IsInitialized()) {
GOOGLE_LOG(ERROR) << InitializationErrorMessage("parse", *message);
return false;
}
return true;
}
//message.cc
bool Message::MergePartialFromCodedStream(io::CodedInputStream* input) {
return WireFormat::ParseAndMergePartial(input, this);
}
再一次回到WireFormat
bool WireFormat::ParseAndMergePartial(io::CodedInputStream* input,
Message* message) {
const Descriptor* descriptor = message->GetDescriptor();
const Reflection* message_reflection = message->GetReflection();
while(true) {
uint32 tag = input->ReadTag();
if (tag == 0) {
// End of input. This is a valid place to end, so return true.
return true;
}
//结束条件
if (WireFormatLite::GetTagWireType(tag) ==
WireFormatLite::WIRETYPE_END_GROUP) {
// Must be the end of the message.
return true;
}
const FieldDescriptor* field = NULL;
if (descriptor != NULL) {
int field_number = WireFormatLite::GetTagFieldNumber(tag);
//根据number查找FieldDescriptor
field = descriptor->FindFieldByNumber(field_number);
// If that failed, check if the field is an extension.
if (field == NULL && descriptor->IsExtensionNumber(field_number)) {
if (input->GetExtensionPool() == NULL) {
field = message_reflection->FindKnownExtensionByNumber(field_number);
} else {
field = input->GetExtensionPool()
->FindExtensionByNumber(descriptor, field_number);
}
}
// If that failed, but we're a MessageSet, and this is the tag for a
// MessageSet item, then parse that.
if (field == NULL &&
descriptor->options().message_set_wire_format() &&
tag == WireFormatLite::kMessageSetItemStartTag) {
if (!ParseAndMergeMessageSetItem(input, message)) {
return false;
}
continue; // Skip ParseAndMergeField(); already taken care of.
}
}
//每次解析一个Field
if (!ParseAndMergeField(tag, field, message, input)) {
return false;
}
}
}
//wire_format_lite.h
inline int WireFormatLite::GetTagFieldNumber(uint32 tag) {
return static_cast<int>(tag >> kTagTypeBits);
}
下面是解析单个Field的函数 wire_format.cc
bool WireFormat::ParseAndMergeField(
uint32 tag,
const FieldDescriptor* field, // May be NULL for unknown
Message* message,
io::CodedInputStream* input) {
const Reflection* message_reflection = message->GetReflection();
enum { UNKNOWN, NORMAL_FORMAT, PACKED_FORMAT } value_format;
if (field == NULL) {
value_format = UNKNOWN;
} else if (WireFormatLite::GetTagWireType(tag) ==
WireTypeForFieldType(field->type())) {
// 这个WIRE FORMAT与 Field应该的type一样
value_format = NORMAL_FORMAT;
} else if (field->is_packable() &&
WireFormatLite::GetTagWireType(tag) ==
WireFormatLite::WIRETYPE_LENGTH_DELIMITED) {
value_format = PACKED_FORMAT;
} else {
// We don't recognize this field. Either the field number is unknown
// or the wire type doesn't match. Put it in our unknown field set.
value_format = UNKNOWN;
}
if (value_format == UNKNOWN) {
return SkipField(input, tag,
message_reflection->MutableUnknownFields(message));
} else if (value_format == PACKED_FORMAT) {// PACKED
uint32 length;
if (!input->ReadVarint32(&length)) return false;
io::CodedInputStream::Limit limit = input->PushLimit(length);
switch (field->type()) {
#define HANDLE_PACKED_TYPE(TYPE, CPPTYPE, CPPTYPE_METHOD) \
case FieldDescriptor::TYPE_##TYPE: { \
while (input->BytesUntilLimit() > 0) { \
CPPTYPE value; \
if (!WireFormatLite::ReadPrimitive< \
CPPTYPE, WireFormatLite::TYPE_##TYPE>(input, &value)) \
return false; \
message_reflection->Add##CPPTYPE_METHOD(message, field, value); \
} \
break; \
}
HANDLE_PACKED_TYPE( INT32, int32, Int32)
HANDLE_PACKED_TYPE( INT64, int64, Int64)
HANDLE_PACKED_TYPE(SINT32, int32, Int32)
HANDLE_PACKED_TYPE(SINT64, int64, Int64)
HANDLE_PACKED_TYPE(UINT32, uint32, UInt32)
HANDLE_PACKED_TYPE(UINT64, uint64, UInt64)
HANDLE_PACKED_TYPE( FIXED32, uint32, UInt32)
HANDLE_PACKED_TYPE( FIXED64, uint64, UInt64)
HANDLE_PACKED_TYPE(SFIXED32, int32, Int32)
HANDLE_PACKED_TYPE(SFIXED64, int64, Int64)
HANDLE_PACKED_TYPE(FLOAT , float , Float )
HANDLE_PACKED_TYPE(DOUBLE, double, Double)
HANDLE_PACKED_TYPE(BOOL, bool, Bool)
#undef HANDLE_PACKED_TYPE
case FieldDescriptor::TYPE_ENUM: {
while (input->BytesUntilLimit() > 0) {
int value;
if (!WireFormatLite::ReadPrimitive<int, WireFormatLite::TYPE_ENUM>(
input, &value)) return false;
const EnumValueDescriptor* enum_value =
field->enum_type()->FindValueByNumber(value);
if (enum_value != NULL) {
message_reflection->AddEnum(message, field, enum_value);
}
}
break;
}
case FieldDescriptor::TYPE_STRING:
case FieldDescriptor::TYPE_GROUP:
case FieldDescriptor::TYPE_MESSAGE:
case FieldDescriptor::TYPE_BYTES:
// Can't have packed fields of these types: these should be caught by
// the protocol compiler.
return false;
break;
}
input->PopLimit(limit);
} else {
// Non-packed value (value_format == NORMAL_FORMAT)
switch (field->type()) {
#define HANDLE_TYPE(TYPE, CPPTYPE, CPPTYPE_METHOD) \
case FieldDescriptor::TYPE_##TYPE: { \
CPPTYPE value; \
if (!WireFormatLite::ReadPrimitive< \
CPPTYPE, WireFormatLite::TYPE_##TYPE>(input, &value)) \
return false; \
if (field->is_repeated()) { \
message_reflection->Add##CPPTYPE_METHOD(message, field, value); \
} else { \
message_reflection->Set##CPPTYPE_METHOD(message, field, value); \
} \
break; \
}
HANDLE_TYPE( INT32, int32, Int32)
HANDLE_TYPE( INT64, int64, Int64)
HANDLE_TYPE(SINT32, int32, Int32)
HANDLE_TYPE(SINT64, int64, Int64)
HANDLE_TYPE(UINT32, uint32, UInt32)
HANDLE_TYPE(UINT64, uint64, UInt64)
HANDLE_TYPE( FIXED32, uint32, UInt32)
HANDLE_TYPE( FIXED64, uint64, UInt64)
HANDLE_TYPE(SFIXED32, int32, Int32)
HANDLE_TYPE(SFIXED64, int64, Int64)
HANDLE_TYPE(FLOAT , float , Float )
HANDLE_TYPE(DOUBLE, double, Double)
HANDLE_TYPE(BOOL, bool, Bool)
#undef HANDLE_TYPE
case FieldDescriptor::TYPE_ENUM: {
int value;
if (!WireFormatLite::ReadPrimitive<int, WireFormatLite::TYPE_ENUM>(
input, &value)) return false;
const EnumValueDescriptor* enum_value =
field->enum_type()->FindValueByNumber(value);
if (enum_value != NULL) {
if (field->is_repeated()) {
message_reflection->AddEnum(message, field, enum_value);
} else {
message_reflection->SetEnum(message, field, enum_value);
}
} else {
// The enum value is not one of the known values. Add it to the
// UnknownFieldSet.
int64 sign_extended_value = static_cast<int64>(value);
message_reflection->MutableUnknownFields(message)
->AddVarint(WireFormatLite::GetTagFieldNumber(tag),
sign_extended_value);
}
break;
}
// Handle strings separately so that we can optimize the ctype=CORD case.
case FieldDescriptor::TYPE_STRING: {
string value;
if (!WireFormatLite::ReadString(input, &value)) return false;
VerifyUTF8String(value.data(), value.length(), PARSE);
if (field->is_repeated()) {
message_reflection->AddString(message, field, value);
} else {
message_reflection->SetString(message, field, value);
}
break;
}
case FieldDescriptor::TYPE_BYTES: {
string value;
if (!WireFormatLite::ReadBytes(input, &value)) return false;
if (field->is_repeated()) {
message_reflection->AddString(message, field, value);
} else {
message_reflection->SetString(message, field, value);
}
break;
}
case FieldDescriptor::TYPE_GROUP: {
Message* sub_message;
if (field->is_repeated()) {
sub_message = message_reflection->AddMessage(
message, field, input->GetExtensionFactory());
} else {
sub_message = message_reflection->MutableMessage(
message, field, input->GetExtensionFactory());
}
if (!WireFormatLite::ReadGroup(WireFormatLite::GetTagFieldNumber(tag),
input, sub_message))
return false;
break;
}
case FieldDescriptor::TYPE_MESSAGE: {
Message* sub_message;
if (field->is_repeated()) {
sub_message = message_reflection->AddMessage(
message, field, input->GetExtensionFactory());
} else {
sub_message = message_reflection->MutableMessage(
message, field, input->GetExtensionFactory());
}
if (!WireFormatLite::ReadMessage(input, sub_message)) return false;
break;
}
}
}
//wire_format_lite_inl.h
inline bool WireFormatLite::ReadMessage(io::CodedInputStream* input,
MessageLite* value) {
uint32 length;
if (!input->ReadVarint32(&length)) return false;
if (!input->IncrementRecursionDepth()) return false;
io::CodedInputStream::Limit limit = input->PushLimit(length);
if (!value->MergePartialFromCodedStream(input)) return false;
// Make sure that parsing stopped when the limit was hit, not at an endgroup
// tag.
if (!input->ConsumedEntireMessage()) return false;
input->PopLimit(limit);
input->DecrementRecursionDepth();
return true;
}
上面的代码也说明了packed只适用于primitive和enum
ReadPrimitive方法:
template <>
inline bool WireFormatLite::ReadPrimitive<int64, WireFormatLite::TYPE_SFIXED64>(
io::CodedInputStream* input,
int64* value) {
uint64 temp;
if (!input->ReadLittleEndian64(&temp)) return false;
*value = static_cast<int64>(temp);
return true;
}
CodedStreamOutput/CodedStreamInput
整数类型的编码就是在这里完成的(见下面一个段落)
主要有以下几个类:
- ZeroCopyInputStream
- ZeroCopyOutputStream
- CodedInputStream
- CodedOutputStream
其中CodedInputStream/CodedOutputStream是对Zero***Stream的封装,允许你对底层流中的字符以不同的形式操作。特别的,这两个类提供了varint编解码实现来编解码一个int。
CodedInputStream
构造函数的参数是一个ZeroCopyInputStream指针:
//coded_stream.h line 1081
inline CodedInputStream::CodedInputStream(ZeroCopyInputStream* input)
: input_(input),
buffer_(NULL),
buffer_end_(NULL),
total_bytes_read_(0),
overflow_bytes_(0),
last_tag_(0),
legitimate_message_end_(false),
aliasing_enabled_(false),
current_limit_(kint32max),
buffer_size_after_limit_(0),
total_bytes_limit_(kDefaultTotalBytesLimit),
total_bytes_warning_threshold_(kDefaultTotalBytesWarningThreshold),
recursion_depth_(0),
recursion_limit_(default_recursion_limit_),
extension_pool_(NULL),
extension_factory_(NULL) {
// Eagerly Refresh() so buffer space is immediately available.
Refresh();
}
CodedInputStream::Refresh()函数负责从input_中得到数据指针。
CodedOutputStream
构造函数的参数是一个ZeroCopyOutputStream指针:
//coded_stream.cc line 553
CodedOutputStream::CodedOutputStream(ZeroCopyOutputStream* output)
: output_(output),
buffer_(NULL),
buffer_size_(0),
total_bytes_(0),
had_error_(false) {
// Eagerly Refresh() so buffer space is immediately available.
Refresh();
// The Refresh() may have failed. If the client doesn't write any data,
// though, don't consider this an error. If the client does write data, then
// another Refresh() will be attempted and it will set the error once again.
had_error_ = false;
}
bool CodedOutputStream::Refresh() {
void* void_buffer;
if (output_->Next(&void_buffer, &buffer_size_)) {
buffer_ = reinterpret_cast<uint8*>(void_buffer);
total_bytes_ += buffer_size_;
return true;
} else {
buffer_ = NULL;
buffer_size_ = 0;
had_error_ = true;
return false;
}
}
ZeroCopyInputStream
ZeroCopy**Stream 的主要思想是,将buffer的开辟这个工作放在流内部,外面只要调用Next()方法,就可以开辟read/write buffer,得到这个buffer的指针,直接读写这块内存就ok了。省了一次memcpy。
这是一个抽象类,主要接口是:
- virtual bool Next(const void* data, int size);
- virtual void BackUp(int count);
- virtual bool Skip();
- virtual int64 ByteCount() const;
ZeroCopyInputStream有几个实现在zero_copy_stream_impl.h
- FileInputStream (取代ifstream)
- IstreamInputStream (包装istream)
- ConcatenatingInputStream ()
- LimitingInputStream (对其他ZeroCopy的带limit的包装器)
IstreamInputStream
//zero_copy_stream_impl.h
class LIBPROTOBUF_EXPORT IstreamInputStream : public ZeroCopyInputStream {
public:
// Creates a stream that reads from the given C++ istream.
// If a block_size is given, it specifies the number of bytes that
// should be read and returned with each call to Next(). Otherwise,
// a reasonable default is used.
explicit IstreamInputStream(istream* stream, int block_size = -1);
~IstreamInputStream();
// implements ZeroCopyInputStream ----------------------------------
bool Next(const void** data, int* size);
void BackUp(int count);
bool Skip(int count);
int64 ByteCount() const;
private:
class LIBPROTOBUF_EXPORT CopyingIstreamInputStream : public CopyingInputStream {
public:
CopyingIstreamInputStream(istream* input);
~CopyingIstreamInputStream();
// implements CopyingInputStream ---------------------------------
int Read(void* buffer, int size);
// (We use the default implementation of Skip().)
private:
// The stream.
istream* input_;
GOOGLE_DISALLOW_EVIL_CONSTRUCTORS(CopyingIstreamInputStream);
};
CopyingIstreamInputStream copying_input_;
CopyingInputStreamAdaptor impl_;
GOOGLE_DISALLOW_EVIL_CONSTRUCTORS(IstreamInputStream);
};
其中CopyingInputStream和CopyInputStreamAdaptor定义在zero_copy_stream_impl_lite.h中。其中CopyInputStream是一个抽象类,只有Read和Skip两个接口。而CopyingInputStreamAdaptor是将CopyInputStream适配到ZeroCopyInputStream的适配器。
还是用一个类图来表达一下:
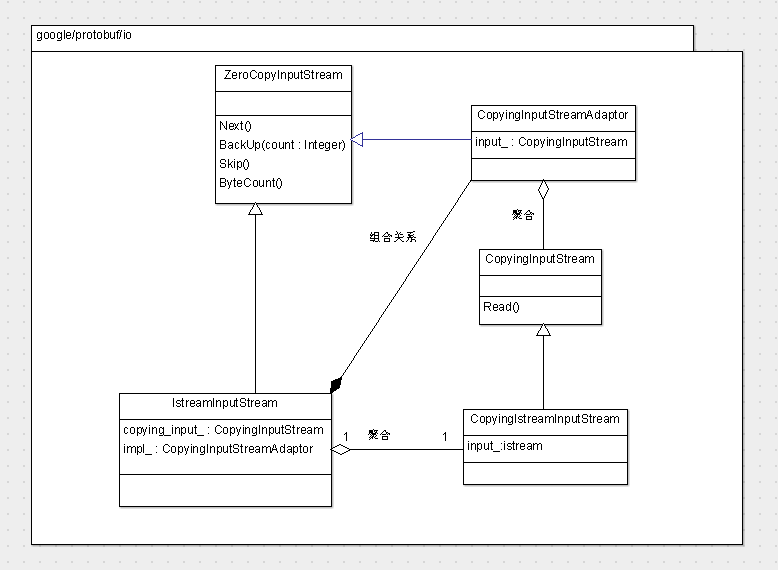
所以如果想实现一个新的拷贝类型的ZeroCopyInputStream,只要提供CopyingInputStream的子类实现就ok了。类似于这里的CopyingFileInputStream和CopyingIstreamInputStream
ZeroCopyOutputStream
这是一个抽象类,主要接口是:
- virtual bool Next(void* data, int size);
- virtual void BackUp(int count);
- virtual int64 ByteCount() const;
有两个主要实现:
- FileOutputStream
- OstreamOutputStream
protobuf编码总结
| ProtoType | CppType | WireFormat | 写策略 | 备注 |
|---|---|---|---|---|
| TYPE_DOUBLE | CPPTYPE_DOUBLE | WIRETYPE_FIXED64 | WriteLittleEndian64(EncodeDouble(value)) | 小端法写入 |
| TYPE_FLOAT | CPPTYPE_FLOAT | WIRETYPE_FIXED32 | WriteLittleEndian32(EncodeFloat(value)) | 小端法写入 |
| TYPE_INT64 | CPPTYPE_INT64 | WIRETYPE_VARINT | WriteVarint64(static_cast |
64变长 |
| TYPE_UINT64 | CPPTYPE_UINT64 | WIRETYPE_VARINT | WriteVarint64(value) | 64变长 |
| TYPE_INT32 | CPPTYPE_INT32 | WIRETYPE_VARINT | WriteVarint32SignExtended | <0 64位变长 |
| TYPE_FIXED64 | CPPTYPE_UINT64 | WIRETYPE_FIXED64 | WriteLittleEndian64 | 小端法写入 |
| TYPE_FIXED32 | CPPTYPE_UINT32 | WIRETYPE_FIXED32 | WriteLittleEndian32 | 小端法写入 |
| TYPE_BOOL | CPPTYPE_BOOL | WIRETYPE_VARINT | WriteVarint32(value ? 1 : 0) | 32变长 |
| TYPE_STRING | CPPTYPE_STRING | WIRETYPE_LENGTH_DELIMITED | WriteVarint32(value.size());WriteString(value) | 32变长 |
| TYPE_GROUP | CPPTYPE_MESSAGE | WIRETYPE_START_GROUP | SerializeWithCachedSizes;WIRETYPE_END_GROUP | |
| TYPE_MESSAGE | CPPTYPE_MESSAGE | WIRETYPE_LENGTH_DELIMITED | WriteVarint32(size);SerializeWithCachedSizes | 长度 + 继续序列化 |
| TYPE_BYTES | CPPTYPE_STRING | WIRETYPE_LENGTH_DELIMITED | WriteVarint32(value.size());WriteString(value) | 长度 + 内容 |
| TYPE_UINT32 | CPPTYPE_UINT32 | WIRETYPE_VARINT | WriteVarint32(value) | 32变长 |
| TYPE_ENUM | CPPTYPE_ENUM | WIRETYPE_VARINT | WriteVarint32SignExtended(value) | <0 64变长 |
| TYPE_SFIXED32 | CPPTYPE_INT32 | WIRETYPE_FIXED32 | WriteLittleEndian32(static_cast |
小端法写入 |
| TYPE_SFIXED64 | CPPTYPE_INT64 | WIRETYPE_FIXED64 | WriteLittleEndian64(static_cast |
小端法写入 |
| TYPE_SINT32 | CPPTYPE_INT32 | WIRETYPE_VARINT | WriteVarint32(ZigZagEncode32(value)) | ZigZag + 变长,适合负数 |
| TYPE_SINT64 | CPPTYPE_INT64 | WIRETYPE_VARINT | WriteVarint64(ZigZagEncode64(value)) | ZigZag + 变长,适合负数 |
其中WireFormat会在每个Value前加上一个Tag(packed只会在repeated开始的时候加)
STRING和BYTES的区别在于前者会做一个VerifyUTF8String
其中Tag是32位的一个整数:
#define GOOGLE_PROTOBUF_WIRE_FORMAT_MAKE_TAG(FIELD_NUMBER, TYPE) \
static_cast<uint32>( \
((FIELD_NUMBER) << ::google::protobuf::internal::WireFormatLite::kTagTypeBits) \
| (TYPE))
WireFormatLite::WriteInt32
WriteTag(field_number, WIRETYPE_VARINT, output)
CodedOutputStream->WriteVarint32SignExtended(value)
下面的几个Write方法都是CodedOutputStream提供的
WriteLittleEndian32
//coded_stream.cc line 612
void CodedOutputStream::WriteLittleEndian32(uint32 value) {
uint8 bytes[sizeof(value)];
bool use_fast = buffer_size_ >= sizeof(value);
uint8* ptr = use_fast ? buffer_ : bytes;
WriteLittleEndian32ToArray(value, ptr);
if (use_fast) {
Advance(sizeof(value));
} else {
WriteRaw(bytes, sizeof(value));
}
}
inline uint8* CodedOutputStream::WriteLittleEndian32ToArray(uint32 value,
uint8* target) {
#if defined(PROTOBUF_LITTLE_ENDIAN) //如果系统自身是小端法表示,直接memcpy,拷过去直接就是小端法。
memcpy(target, &value, sizeof(value));
#else
target[0] = static_cast<uint8>(value);
target[1] = static_cast<uint8>(value >> 8);
target[2] = static_cast<uint8>(value >> 16);
target[3] = static_cast<uint8>(value >> 24);
#endif
return target + sizeof(value);
}
WriteLittleEndian64
和上面类似
WriteVarint32
void CodedOutputStream::WriteVarint32(uint32 value) {
if (buffer_size_ >= kMaxVarint32Bytes) {
// Fast path: We have enough bytes left in the buffer to guarantee that
// this write won't cross the end, so we can skip the checks.
uint8* target = buffer_;
uint8* end = WriteVarint32FallbackToArrayInline(value, target);
int size = end - target;
Advance(size);
} else {
// Slow path: This write might cross the end of the buffer, so we
// compose the bytes first then use WriteRaw().
uint8 bytes[kMaxVarint32Bytes];
int size = 0;
while (value > 0x7F) {
bytes[size++] = (static_cast<uint8>(value) & 0x7F) | 0x80;
value >>= 7;
}
bytes[size++] = static_cast<uint8>(value) & 0x7F;
WriteRaw(bytes, size);
}
}
inline uint8* CodedOutputStream::WriteVarint32FallbackToArrayInline(
uint32 value, uint8* target) {
target[0] = static_cast<uint8>(value | 0x80);
if (value >= (1 << 7)) {
target[1] = static_cast<uint8>((value >> 7) | 0x80);
if (value >= (1 << 14)) {
target[2] = static_cast<uint8>((value >> 14) | 0x80);
if (value >= (1 << 21)) {
target[3] = static_cast<uint8>((value >> 21) | 0x80);
if (value >= (1 << 28)) {
target[4] = static_cast<uint8>(value >> 28);
return target + 5;
} else {
target[3] &= 0x7F;
return target + 4;
}
} else {
target[2] &= 0x7F;
return target + 3;
}
} else {
target[1] &= 0x7F;
return target + 2;
}
} else {
target[0] &= 0x7F;
return target + 1;
}
}
WriteVarint64
类似上面
WriteVarint32SignExtended
//coded_stream.h line 944
inline void CodedOutputStream::WriteVarint32SignExtended(int32 value) {
if (value < 0) {
WriteVarint64(static_cast<uint64>(value));
} else {
WriteVarint32(static_cast<uint32>(value));
}
}
WriteString
//coded_stream.h line 1028
inline void CodedOutputStream::WriteString(const string& str) {
WriteRaw(str.data(), static_cast<int>(str.size()));
}
//coded_stream.cc line 593
void CodedOutputStream::WriteRaw(const void* data, int size) {
while (buffer_size_ < size) {
memcpy(buffer_, data, buffer_size_);
size -= buffer_size_;
data = reinterpret_cast<const uint8*>(data) + buffer_size_;
if (!Refresh()) return;
}
memcpy(buffer_, data, size);
Advance(size);
}
ZigZagEncode32
//wire_format_lite.h line 600
inline uint32 WireFormatLite::ZigZagEncode32(int32 n) {
// Note: the right-shift must be arithmetic
return (n << 1) ^ (n >> 31);
}
inline int32 WireFormatLite::ZigZagDecode32(uint32 n) {
return (n >> 1) ^ -static_cast<int32>(n & 1);
}
inline uint64 WireFormatLite::ZigZagEncode64(int64 n) {
// Note: the right-shift must be arithmetic
return (n << 1) ^ (n >> 63);
}
inline int64 WireFormatLite::ZigZagDecode64(uint64 n) {
return (n >> 1) ^ -static_cast<int64>(n & 1);
}